弊社では、いくつか自社開発のシステムの運用を行っています。これらのシステムが稼働している際に最も障害が起きてほしくないサーバといえば……やはり、ダントツでデータベース関連のサーバです。これはもうどうしようもなく圧倒的にデータベースでしょう。
それでも、起きてしまう障害には対処しなければなりませんし、データが破損しないよう準備は行っておく必要があります。
今回は、弊社で構築しているシステムで主に使用している PostgreSQL データベースのレプリケーションの仕組みや設定について、簡単に説明したいと思います。
この記事の内容
ストリーミングレプリケーションとは
データベースに大切なデータを保存するにあたって、サーバー自体の耐障害性が大事なことはもちろんですが、万が一障害が発生した場合にも対処ができるよう、バックアップの他に レプリカ(複製) を作成することで障害が発生していても継続して稼働できる可用性の高いシステムを構築することができます。
PostgreSQLのレプリケーションには、データベース全体を複製する ストリーミングレプリケーション(物理レプリケーション) と、テーブルやデータベースごとに複製する ロジカルレプリケーション(論理レプリケーション) があります。
今回説明する、ストリーミングレプリケーションは、プライマリサーバの更新情報をスタンバイサーバに転送することで、プライマリサーバとスタンバイサーバのデータベースを同じ状態に保つことができる…というものです。
ストリーミングレプリケーションの仕組み
PostgreSQL の標準機能であるストリーミングレプリケーションは、プライマリサーバ側で発生した更新情報を、スタンバイサーバーに側にリアルタイムで転送することで、プライマリサーバとスタンバイサーバのデータベースを同じ状態にするというものです。
PostgreSQL は、クラッシュリカバリーやロールバックに備えて、プライマリサーバの更新情報を トランザクションログ として保存します。これを WAL (Write-Ahead Log) と言います。ストリーミングレプリケーションは、リアルタイムにこの WAL をスタンバイサーバへ転送し、スタンバイサーバでその WAL を適用することで、プライマリサーバと同じ更新をスタンバイサーバで行います。
wal sender と wal reciever プロセス
プライマリサーバとスタンバイサーバでの WAL のやりとりは、プライマリサーバ側の wal sender プロセスと、スタンバイサーバー側の wal receiver プロセスで行われます。いくつかの設定ファイルに設定を行うことで、これらのプロセスが起動されます。プライマリサーバ / スタンバイサーバそれぞれで設定するファイルや設定内容が異なります。
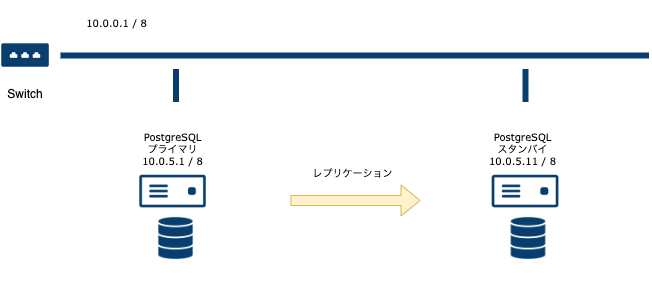
今回の構成と設定
今回は Debian(buster) をインストールしたサーバーを2台用意し、それぞれソースコードから PostgreSQL 13.3 をコンパイルしてインストールしました。
プライマリサーバ側の設定
インストール後、以下の手順でプライマリサーバ側の設定を行っていきます。
- レプリケーションユーザ作成
postgres@pgdb1m:~$ psql postgres=# CREATE USER repl WITH REPLICATION; CREATE ROLE postgres=# \du postgres | Superuser, Create role, Create DB, Replication, Bypass RLS | {} repl | Replication | {} - Config 設定
postgresql.confwal_level = replica max_wal_senders = 5 synchronous_standby_names = '*'
上記の設定が終わったら、PostgreSQL のプロセスを再起動します。これでレプリケーションを行うプライマリサーバ側の設定は完了です。
セカンダリサーバ側の設定
- プライマリの複製
念の為、data ディレクトリを保存し、 pg_basebackup コマンド を使ってプライマリの複製を行います。
postgres@pgdb1s:~$ cd ~
postgres@pgdb1s:~$ mv data data.org
postgres@pgdb1s:~$ pg_basebackup -R -h 10.0.5.1 -p 5432 -U repl -D ./data-R オプションを指定すると postgresql.auto.conf ファイルが作成されます。このファイルにはプライマリサーバへの接続情報など、レプリケーションを行うための設定が以下のように自動で記載されます。これはものすごく便利で、本当に楽ですね。
postgres@pgdb1s:~/data$ cat ./postgresql.auto.conf
# Do not edit this file manually!
# It will be overwritten by the ALTER SYSTEM command.
primary_conninfo = 'user=repl passfile=''/opt/komari/pgsql/.pgpass'' channel_binding=prefer host=10.0.5.1 port=5432 sslmode=prefer sslcompression=0 ssl_min_protocol_version=TLSv1.2 gssencmode=disable krbsrvname=postgres target_session_attrs=any'- Config の書き換え
一部、Config ファイルを書き換えます。
postgresql.conflisten_addresses = 'localhost,10.0.5.11' #max_wal_senders = 10 #synchronous_standby_names = '*' hot_standby = on
プライマリ側と同様に設定が終わったら、PostgreSQL のプロセスを再起動します。これでスタンバイサーバ側の設定も完了です。
レプリケーション状態の確認
それぞれ再起動したら、 プライマリ / スタンバイ のプロセスの状態を systemctl status を使って確認した後、レプリケーションのステータスをプライマリサーバ側で確認します。
SQL コマンドを psql から実行すると、 state や sync_state などレプリケーションの状態が確認できます。何かレプリケーション関連でトラブルがあった際にもこのコマンドを使うことになると思います。
postgres=# select * from pg_stat_replication;
:
state = streaming
sync_state = syncレプリカ(複製)の便利な利用方法
弊社のシステムの環境では、プライマリーサーバの障害時に複製のスタンバイサーバをフェイルオーバーさせることを主な目的としていますが、ストリーミングレプリケーションにはこれ以外の利用方法もあります。
リードオンリースレーブ
ストリーミングレプリケーションが設定されたスタンバイ側のデータベースへのアクセスは参照のみしかできませんが、逆に、複製されたデータベースを参照のみで利用することで、システム全体でより多くの処理をさせることができます。データの読み込みしか必要としないバッチ処理などをスタンバイ側のサーバで行うことで、プライマリサーバの負荷を分散することができます。
今回設定した内容だけでも、スタンバイサーバをリードオンリースレーブとして利用することができます。
遠隔地でのバックアップ
スタンバイサーバを遠隔地にあるサーバにすることで、データを全く別のインフラに保存することもできるので、データセンター自体の災害の対策にもなります。構成上問題がなければ、レプリケーションを使った遠隔バックアップを比較的容易に行うことが可能です。
ストリーミングレプリケーションは、 1対N の構成で構築することができるので、複数のスタンバイサーバに同時にレプリケーションすることができます。1つはプライマリと同一ネットワークに、もう1つは遠隔地に……という構成も可能です。
まとめ
今回は PostgreSQL のストリーミングレプリケーションの設定について書かせていただきました。
個人的には、MySQL の経験の方が長いのですが、環境構築する上での考え方についての差はありませんし、もしかすると、運用面ではスタンバイ用のバックアップ専用ツール ’pg_basebackup' が便利な PostgreSQL の方が扱い易いかもしれません。
機会があればフェイルオーバー時の挙動やプライマリー側障害時の復旧方法などについてもまとめてみようと思います。